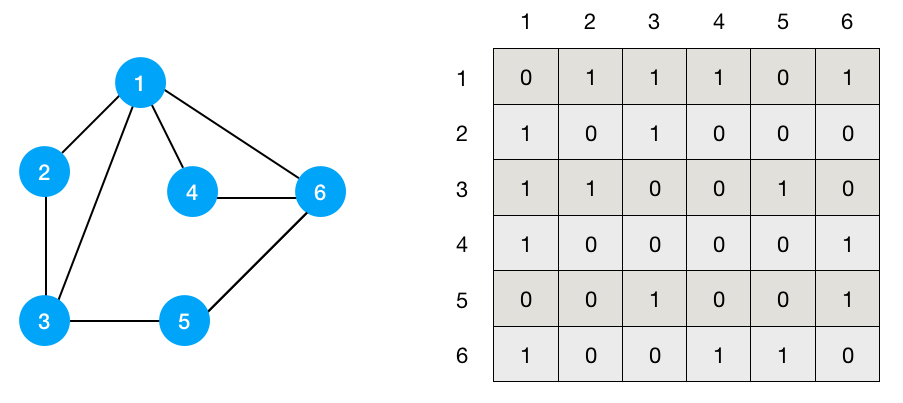
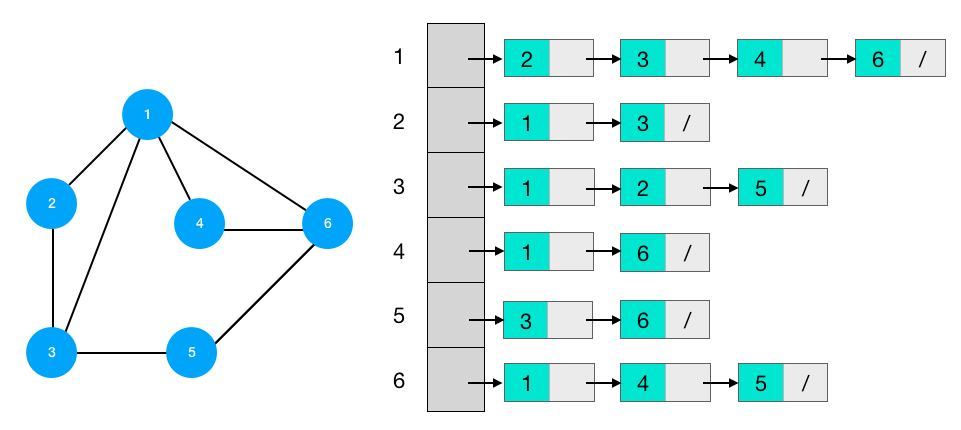
버블 정렬
버블 정렬은 선택 정렬처럼 제일 큰 원소를 끝자리로 옮기는 작업을 반복한다.
단 선택 정렬이 가장 큰 수를 찾은 다음 맨 오른쪽 수와 바꾸는 반면, 버블 정렬은 왼쪽부터 이웃한 수를 비교하면서 순서가 제대로 되어있지 않으면 하나하나 바꾸어나간다.

버블 정렬 구현
public class BubbleSort {
public static void main(String[] args) {
int[] arrays = new int[]{8, 31, 48, 73, 3, 65, 20, 29, 11, 15};
int temp;
int size = arrays.length;
for (int i = 0; i < size; i++) {
for (int j = 0; j < size - 1 - i; j++) {
if (arrays[j] > arrays[j + 1]) {
temp = arrays[j];
arrays[j] = arrays[j + 1];
arrays[j + 1] = temp;
}
}
}
}
}
'Algorithm' 카테고리의 다른 글
| [Algorithm] 퀵 정렬 (Quick Sort) (0) | 2019.11.23 |
|---|---|
| [Algorithm] 병합 정렬 (Merge Sort) (0) | 2019.11.23 |
| [Algorithm] 삽입 정렬 (Insertion Sort) (0) | 2019.11.21 |
| [Algorithm] 선택 정렬 (Selection Sort) (0) | 2019.11.20 |
| [Algorithm] 그래프 - 그래프의 표현 (0) | 2019.11.17 |

kyungseop
공부한 내용 정리